To wrap up this bespoke residency, now that our 6 months (part-time) has come to an end, I thought it would be helpful to cover a bunch of ideas and workflows we’ve established, some problems, and future directions to explore. There’s a lot to unpack, but I’ll try and be succinct – with a few digressions.
Here’s a video that covers the main points, which I expand upon in the text below.
During the course of this residency I’ve conducted lots of experiments and had a great dialogue with Chris about how to approach things, leading down some inspiring pathways for future work.
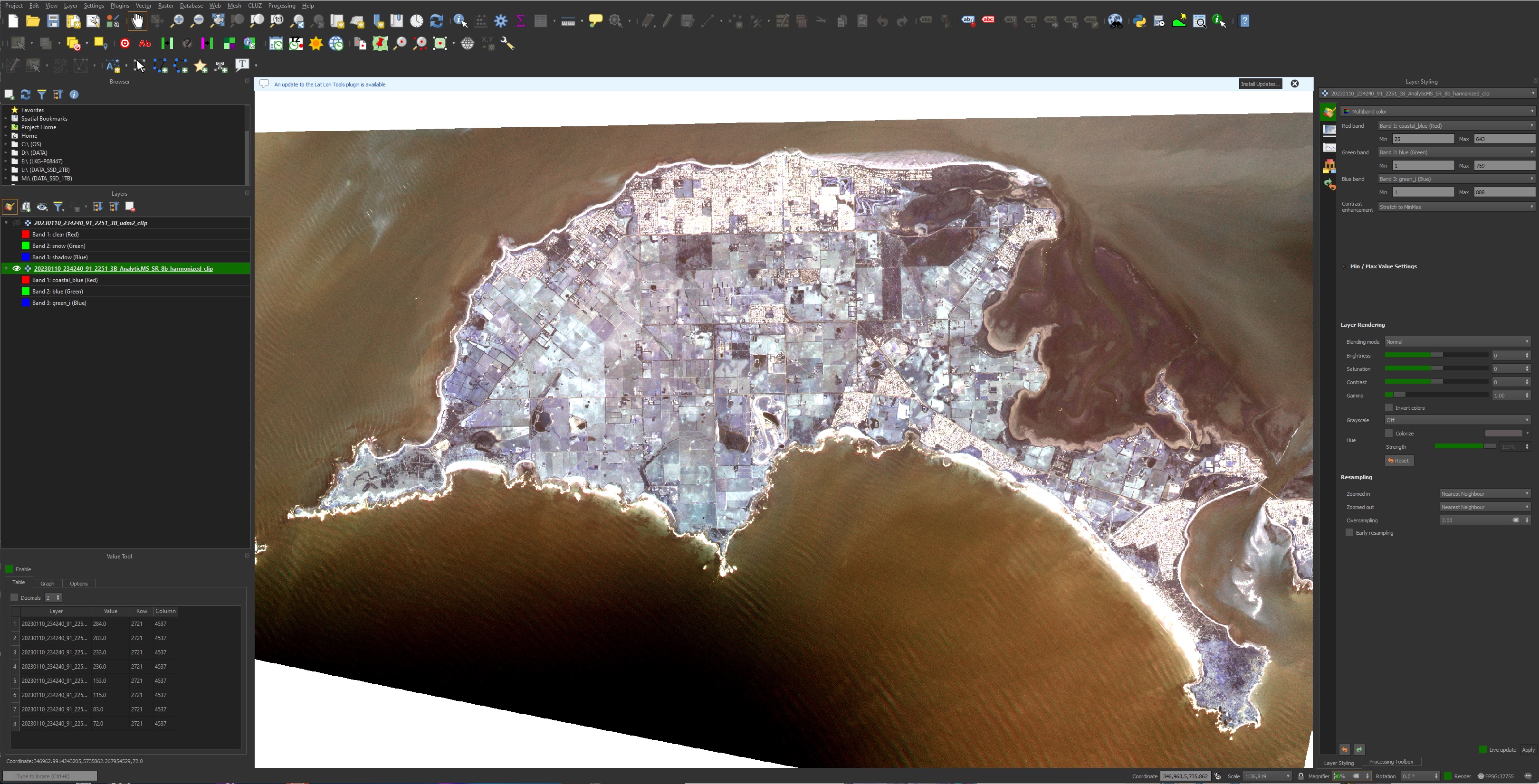
2D visualisation
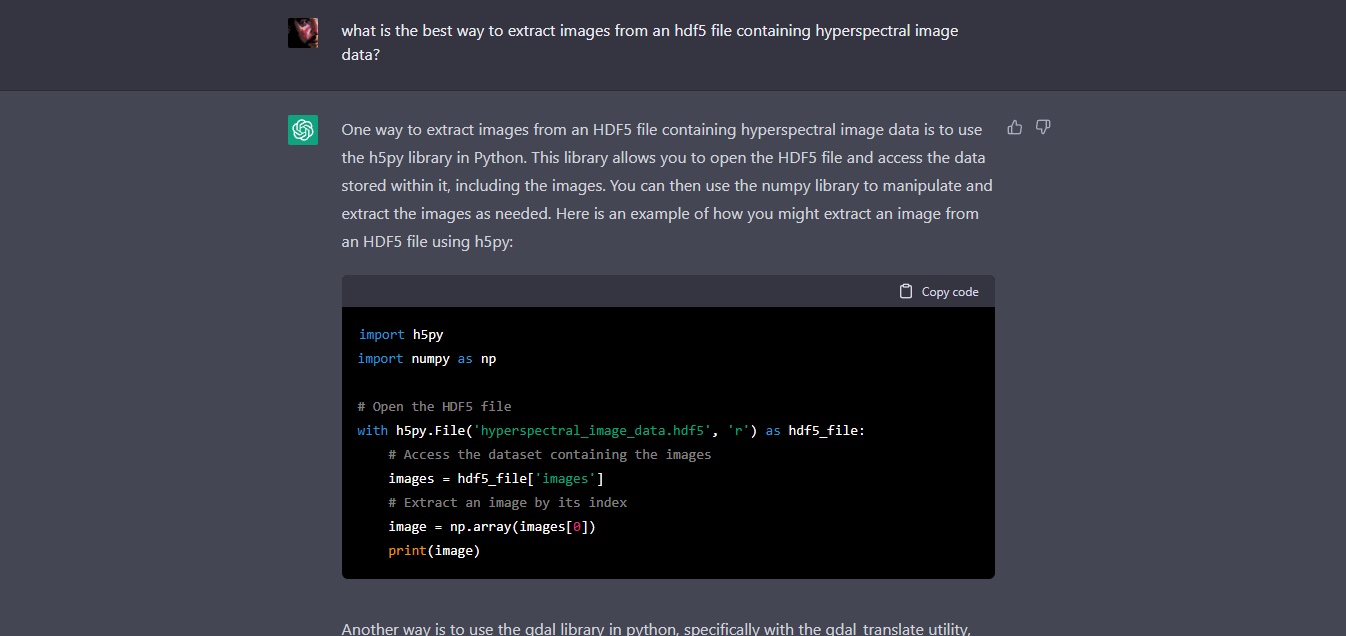
Initially we started off with looking at how to visualise hyperspectral and multispectral satellite data – and it turns to be pretty straight-forward using Python and some programming help using AI – a great way to develop ~explained~ code for libraries one may be unfamiliar with.
You need to know how to iterate and debug a program, work through some documentation, and the data can be accessed in complex file formats and transformed into usable images. This can be done in Juypiter notebooks, running locally in e.g. Anaconda, or remotely on Google Colab or NCRIS Cloudstor notebooks. Pretty straight-forward. These programming assistants will significantly improve over time and complex tasks will become even simpler to prompt.
What the data captures is an entirely different matter – and hyperspectral data is a lot more complicated than multispectral data. I explored a raycasting volume system for that in UE, but that is beyond the remit of this wrap-up. There are lots of different ways to approach it – the question is which one is most useful. It’s a bit “chicken and egg.”
In concert, the question arises as to what one can infer from the data – which is in itself a huge field of scientific and engineering research. It’s not just a matter of applying some kind of GIS colour palette to spectral data – there’s whole fields of analytics that can be applied. These range from naïve naked-eye approaches, through quantitative and statistical analyses to fascinating work in deep learning .
What we have attempted to do is to move this data from the exclusive purview of the specialist to the generalist, from the desktop GIS system to the spatially-located mobile device where an observer may ~actually~ be in a moment in time, and to establish how a human-AI interaction might be established that can create dialogue, queries and observations about the data and their immediate environment.
3D+ Visualisation
Similar approaches can be undertaken in Python for creating 3D+ representations of data, using e.g. MatPlotLib or VisPy (amongst many others).
For our purposes, Python scripts can run in Unreal Engine/ Omniverse platforms (as well as Unity) and become involved in the creation of geometry, textures, actors and a whole range of actions and narrative entities, Very interesting to see how this is opening up as a result of Virtual Production pipelines, upon which art/science projects can piggyback. This includes creating complex time series animations, physics simulations and volumetric rendering, including interactions with other toolsets used in scientific visualisation and creative industries workflows. Python is the lingua franca.
Cesium
Cesium for Unreal has progressed a great deal. It is currently more stable and flexible than implementations for Omniverse or Unity. I surmise that this is because of the source-available nature of Unreal, as opposed to the closed-source model of the other platforms. Smart move by Epic. I hope it stays that way and becomes more open over time. Cesium is opensource, which is crucial to its flexibility and widespread adoption.
AI and ML
Of course, the elephant in the room is Artificial Intelligence and Machine Learning. It has been fascinating to watch this evolve over the past 6 months – a huge hype-cycle reminiscent of the Blockchain frenzy of the last few years – but at least blockchain was never represented as an ‘existential risk’ . Nevertheless, quantum blockchain technologies will, some day, become human-actor authentication and provenential authorities for lots of different types of data – it may become the only way to distinguish between ‘real’ and generative datasets.
AI is the definitive enabling technology of our time. It present risks (not yet existential ones) and great opportunities. Like any powerful technology it must be treated with great circumspection and aligned with scientific and ethical interests for the benefit of ‘humanity’. It’s a mirror of humanity, and humanity is not all good. Artistic engagement can help explore and critique this new domain.
XR
David Chalmer’s Reality+ (2022) stimulates thoughts about the interfusion of world, data and intention, as does Jeff Malpas’ Place and Experience: A Philosophical Topography (2nd Ed. 2018) and Peter Otto’s Multiplying Worlds: Romanticism, Modernity and the Emergence of Virtual Reality (2011).
Apple’s Vision Pro is the latest technological offering in this long history of the intermediation of the self, panorama and place. And it is compelling – not because of the artificial gaze projected to the outside world (deixis to the other), but because of the disposal of controllers – that it can operate by coded hand-gesture alone. Its parts are not new, but the bringing together of systems is. It looks very interesting.
Yet the price of all ‘complete’ XR is total surveillance, even with a ‘secure enclave’: it’s still a head in a box, inherently panoptic and performative.
One wonders how long it will be before we all need to start wearing tinfoil hats to resist implanted thoughts or inception. Quite a long time, I expect, but not forever. Besides, the notion of implanted thoughts is epistemically ambiguous – often these are simply referred to as ‘culture’, ‘beliefs’ and ‘language’. It’s all quite problematic in the post-truth, post-human world of the Novacene. More to contemplate.
Some Practical Examples

In these naive and early days of AI XR, the world that is opening up is fascinating, as I hope the brief sketches above demonstrate. I think of them simply as sketches in exploring how XR will become continuous across mobile devices, HMDs/spectacles and desktop and large immersive screens. Each device format has its own affordances and content, interactions and UI/UX needs to be cognizant of that – lots of interesting design considerations. Natural interactions seem the most compelling, as the premise of ubiquitous/ambient computing is that it will disappear into the background and essentially become invisible – except for intermediation with the world via AI agents such as our idea of the Geon.
I hope you’ve found the material I’ve covered here as interesting, useful and thought provoking as I have! My sincere thanks to Prof. Chris Fluke, the SmartSat CRC and ANAT for facilitating this absorbing residency. Lots to think about and lots of ideas for future work.