An interesting github repo to keep an eye on – a way to run a private LLM instance and train it on a local document repository – with no internet connection required (once it’s installed!). It uses GPT4all, LlamaCpp, LangChain and a local vector database (not Pinecone, I assume).
I can imagine lots of use cases for this: training upon your own files could enable a useful personal assistant that is ~private~. Imagine it as a memory assistant for all those millions of forgotten files on your computer.
Or as a Zotero assistant for working through academic papers and making connections.
Or as a way of making searchable documentation of software – one could scrape all the Unreal Engine documentation using beautifulsoup and then train on it.
Or for an Arts organisation (like ANAT!) – train on years of office data to create a kind of corporate memory.
Of course, it would still have the hallucination problem, but this could be mitigated by combining it with some sort of web search or other confirmation mechanism.
It’s always problematic making predictions – especially in times of huge technosocial change and disruption. We are experiencing one now (though it may not seem so apparent in day-to-day life) – important aspects need to be identified, and how they will evolve and move forward over the next decade. There are going to be huge, transformational impacts over the immediate future and, especially, our children’s lifetimes.
The principle emergent technology to understand is definitively AI – nothing else comes close, because it is so all-encompassing. Large Language Models are springing up everywhere, with surprising competencies, many of them opensource [1][2][3] and suitable for training upon domain-specific knowledges [4] as well as general tasks.
Thinking of these emergent capabilities, in the context of the current AI arms-race, the issue of human-AI alignment [8] [9] is of crucial regulatory importance:
Ultimately, to figure out what we really need to worry about, we need better AI literacy among the general public and especially policy-makers. We need better transparency on how these large AI systems work, how they are trained, and how they are evaluated. We need independent evaluation, rather than relying on the unreproducible, “just trust us” results in technical reports from companies that profit from these technologies. We need new approaches to the scientific understanding of such models and government support for such research.
Indeed, as some have argued, we need a “Manhattan Project of intense research” on AI’s abilities, limitations, trustworthiness, and interpretability, where the investigation and results are open to anyone. [9]
Although the above concerns sound like science fiction, they are not, and the consequence is that anyone working with AI development (which basically means anyone who interacts with AI systems) must situate themselves within an ethical discourse about consequences that may arise from the use of this technology.
Of course, we have all been doing this for many years through social media and recommender systems – like Amazon, Facebook, VK, Weibo , Pinterest, Etsy – and Google, Microsoft, Apple, Netflix, Tesla, Uber, AirBnB etc. – and the millions of data-mining subsidiary industries that have built up around these. Subsidiary re-brands, data-farms, click-farms, bots, credit agencies, an endless web of information with trillions of connections.
In reference to Derrida, I might whimsically call this ‘n-Grammatology” – given that the pursuit of n-grams has arrived us at this point for the ambiguous machines [10]. A point where the ostensive factivity of science meets the ambiguous epistemology and hermeneutics of embeddings in a vector space – the ‘black box’.
What we know is that AI is a ‘black box’ and that our minds are a ‘black box’, but we have little idea of how similar those ignorances are. They will perhaps be defined by counter-factuals, by what they are not.
Myth
One of the mythologies that surrounds AI that is hard to avoid is that it occurs ‘somewhere else’ on giant machines run by megacorporations or imaginary aliens:
However, as the interview with Hinton above indicates, what has been achieved is an incredible level of compression : a 1-trillion parameter LLM is about 1 terabyte in size:
What this seems to imply is that the kernel will easily fit onto mobile, edge-compute and iOT devices in the near future (e.g. Jetson Nano), and that these devices will probably be able to run independent multimodal AIs.
“AI” is essentially a kind of substrate-independent non-human intelligence, intrinsically capable of global reproduction across billions of devices. It is hard to see how it will not proliferate (with human assistance, initially) into this vast range of technical devices and become universally distributed, rather than existing solely as a service delivered online via APIs controlled by corporations and governments.
AI ‘Society’
The future of AI is not some kind of Colossus, but rather a kind of of global community of ambient interacting agents – a society. Like any society it will be complex, political and ideological – and throw parties:
Exactly how humans fit into this picture will require some careful consideration. Whether the existential risks come to pass are out of the control of most people, by definition. We will essentially be witnesses to the process, with very little opportunity to affect the direction in which it goes in the context of competition between state and corporate actors.
The moment when a human-level AGI emerges will be a singular historic rupture. It seems only a matter of time, an alarmingly short one.
For the next post I will put aside these speculative concerns, and detail some of the steps we have made towards developing a system that incorporates AI, ambient XR and Earth observation. My hope is that this will make some small contribution to a useful and ethical application of the technology.
[4] philschmid blog. “How to Scale LLM Workloads to 20B+ with Amazon SageMaker Using Hugging Face and PyTorch FSDP,” May 2, 2023. https://www.philschmid.de/sagemaker-fsdp-gpt. https://www.philschmid.de/sagemaker-fsdp-gpt
[5] Shinn, Noah, Beck Labash, and Ashwin Gopinath. “Reflexion: An Autonomous Agent with Dynamic Memory and Self-Reflection.” arXiv, March 20, 2023. https://doi.org/10.48550/arXiv.2303.11366.
Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4 [Ope23], was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT4 is part of a new cohort of LLMs (along with ChatGPT and Google’s PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4’s performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4’s capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
Over the last couple of weeks I’ve spent some time virtually attending Nvidia’s GTC Developer Conference, which has been very illuminating. The main take-aways for me have been about how, now that we’re in the Age of AI, that it’s time to really start working with cloud services – and that they’re actually becoming affordable for individuals to use.
Of course, like most computer users, I use cloud services every day – most consumer devices already use them – like Netflix, iCloud, AppleTV, Google Drive, Cloudstor, social media etc. These are kind of passive, invisible services that one uses as part of entertainment, information or storage systems. More complicated systems for developers include things like Google Colab, Amazon Web Services (AWS), Microsoft Azure and Nvidia Omniverse, amongst others.
So this is where AI comes in in a strong way – providing the ability to ingest and summarise prodigious volumes of data and information – and hallucinate rubbish – and this is clearly going to be the way of the future. The AI race is on – here are some interesting (but probably already dated) insights from the AI Index by the Stanford Institute for Human-Centered Artificial Intelligence that are worth absorbing:
Industry has taken over AI development from academia since 2014.
Performance saturation on traditional benchmarks has become a problem.
AI can both harm and help the environment, but new models show promise for energy optimization.
AI is accelerating scientific progress in various fields.
Incidents related to ethical misuse of AI are on the rise.
Demand for AI-related skills is increasing across various sectors in the US (and presumably globally)
Private investment in AI has decreased for the first time in the last decade (but after an astronomical rise in that decade)
Proportion of companies adopting AI has plateaued, but those who have adopted continue to pull ahead.
Policymaker interest in AI is increasing globally.
Chinese citizens are the most positive about AI products and services, while Americans are among the least positive.
“Why? There’s no hope in hell that companies are going to stop working on AI models voluntarily. There’s too much money at stake. And there’s also no hope in hell that countries are going to impose a moratorium to prevent companies from working on AI models. There’s no historical precedent for such geopolitical coordination.
The letter’s call for action is thus hopelessly unrealistic. And the reasons it gives for this pause are hopelessly misguided. We are not on the cusp of building artificial general intelligence, or AGI, the machine intelligence that would match or exceed human intelligence and threaten human society. Contrary to the letter’s claims, our current AI models are not going to “outnumber, outsmart, obsolete and replace us” any time soon.
In fact, it is their lack of intelligence that should worry us”
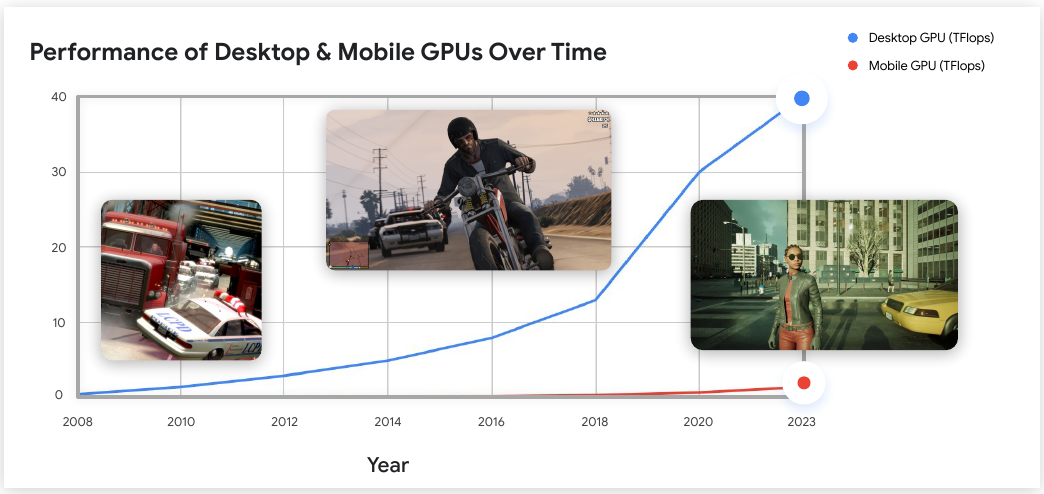
The upshot of this, for the work Chris and I are doing, is clearly that we need to embrace AI-in-XR in the development of novel modalities for Earth Observation using Mixed Reality. It’s simply not going to be very compelling doing something as simple as, for example, visualising data in an XR application (such as an AR phone app) that overlays the scene. I’ve now seen many clunky examples of this, and none of them seem especially compelling, useful or widely adopted. The problem really comes down to the graphics capabilities of mobile devices, as this revealing graph demonstrates:
A potential solution arrives with XR ‘in the cloud’ – and it is evident from this year’s GTC that all the big companies are making a big play in this space and a lot of infrastructure development is going on – billions of dollars of investment. And it’s not just ‘XR’ but “XR with AI’ and high-fidelity, low-latency pixel-streaming. So, my objective is to ride on the coat-tails of this in a low-budget arty-sciencey way, and make the most of the resources that are now becoming available for free (or low-cost) as these huge industries attempt to on-board developers and explore the design-space of applications.
As you might imagine, it has been frustratingly difficult to find documentation and examples of how to go about doing this, as it is all so new. But this is what you expect with emergent and cutting-edge technologies (and almost everyone trying to make a buck off them) – but it’s thankfully something I am used to from my own practice and research: chaining together systems and workflows in the pursuit of novel outcomes.
It’s been a lot to absorb over the last few weeks, but I’m now at the stage where I can begin implementing an AI agent (using the OpenAI API) that one can query with a voice interface (and yes, it talks back), running within a cloud-hosted XR application suitable for e.g. VR HMDs, AR mobile devices, and mixed-reality devices like the Hololens 2 (I wish I had one!). It’s just a sketch at this stage, but I can see the way forward if/when I can get access to the GPT-4 API and plugin architecture, to creating a kind of Earth Observation ‘Oracle’ and a new modality for envisioning and exploring satellite data in XR.
Currently I’m using OpenAI GPT3.5-turbo and playing around with a local install of GPT4-x_Alpaca and AutoGPT, and local pixel-streaming XR. The next step is to move this over to Azure CloudXR and Azure Cognitive Services. Of course, its all much more complicated than it sounds, so I expect a lot of hiccups along the way, but nothing insurmountable.
I’ll post some technical details and (hopefully) some screencaps in a future post.