





A better way to share Earth observation data
privateGPT
An interesting github repo to keep an eye on – a way to run a private LLM instance and train it on a local document repository – with no internet connection required (once it’s installed!). It uses GPT4all, LlamaCpp, LangChain and a local vector database (not Pinecone, I assume).
https://github.com/imartinez/privateGPT
I can imagine lots of use cases for this: training upon your own files could enable a useful personal assistant that is ~private~. Imagine it as a memory assistant for all those millions of forgotten files on your computer.
Or as a Zotero assistant for working through academic papers and making connections.
Or as a way of making searchable documentation of software – one could scrape all the Unreal Engine documentation using beautifulsoup and then train on it.
Or for an Arts organisation (like ANAT!) – train on years of office data to create a kind of corporate memory.
Of course, it would still have the hallucination problem, but this could be mitigated by combining it with some sort of web search or other confirmation mechanism.
Interesting!
Pinecone, LangChain, Image Embeddings
Pinecone: https://www.pinecone.io/learn/vector-database/
LangChain AI Handbook: https://www.pinecone.io/learn/langchain/
Embedding Methods for Image Search: https://www.pinecone.io/learn/image-search/

AI XR in the Cloud

Over the last couple of weeks I’ve spent some time virtually attending Nvidia’s GTC Developer Conference, which has been very illuminating. The main take-aways for me have been about how, now that we’re in the Age of AI, that it’s time to really start working with cloud services – and that they’re actually becoming affordable for individuals to use.
Of course, like most computer users, I use cloud services every day – most consumer devices already use them – like Netflix, iCloud, AppleTV, Google Drive, Cloudstor, social media etc. These are kind of passive, invisible services that one uses as part of entertainment, information or storage systems. More complicated systems for developers include things like Google Colab, Amazon Web Services (AWS), Microsoft Azure and Nvidia Omniverse, amongst others.
In Australian science programmes there are National Computing Infrastructure (NCI) services such as AuScope Virtual Research Environments, Digital Earth Australia (DEA), Integrated Marine Observing System (IMOS), Australian Research Data Commons (ARDC), and even interesting history and culture applications built atop these such as the Time Layered Cultural Map of Australia (TLCMap). Of course, there are dozens more scattered around various organisations and websites – it’s all quite difficult to discover amidst the acronyms, let alone keep track of, so any list will always be partial and incomplete.
So this is where AI comes in in a strong way – providing the ability to ingest and summarise prodigious volumes of data and information – and hallucinate rubbish – and this is clearly going to be the way of the future. The AI race is on – here are some interesting (but probably already dated) insights from the AI Index by the Stanford Institute for Human-Centered Artificial Intelligence that are worth absorbing:
- Industry has taken over AI development from academia since 2014.
- Performance saturation on traditional benchmarks has become a problem.
- AI can both harm and help the environment, but new models show promise for energy optimization.
- AI is accelerating scientific progress in various fields.
- Incidents related to ethical misuse of AI are on the rise.
- Demand for AI-related skills is increasing across various sectors in the US (and presumably globally)
- Private investment in AI has decreased for the first time in the last decade (but after an astronomical rise in that decade)
- Proportion of companies adopting AI has plateaued, but those who have adopted continue to pull ahead.
- Policymaker interest in AI is increasing globally.
- Chinese citizens are the most positive about AI products and services, while Americans are among the least positive.
Nevertheless, it is clear to me that the so-called ‘Ai pause‘ is not going to happen – as Toby Walsh observes:
“Why? There’s no hope in hell that companies are going to stop working on AI models voluntarily. There’s too much money at stake. And there’s also no hope in hell that countries are going to impose a moratorium to prevent companies from working on AI models. There’s no historical precedent for such geopolitical coordination.
The letter’s call for action is thus hopelessly unrealistic. And the reasons it gives for this pause are hopelessly misguided. We are not on the cusp of building artificial general intelligence, or AGI, the machine intelligence that would match or exceed human intelligence and threaten human society. Contrary to the letter’s claims, our current AI models are not going to “outnumber, outsmart, obsolete and replace us” any time soon.
In fact, it is their lack of intelligence that should worry us”
The upshot of this, for the work Chris and I are doing, is clearly that we need to embrace AI-in-XR in the development of novel modalities for Earth Observation using Mixed Reality. It’s simply not going to be very compelling doing something as simple as, for example, visualising data in an XR application (such as an AR phone app) that overlays the scene. I’ve now seen many clunky examples of this, and none of them seem especially compelling, useful or widely adopted. The problem really comes down to the graphics capabilities of mobile devices, as this revealing graph demonstrates:
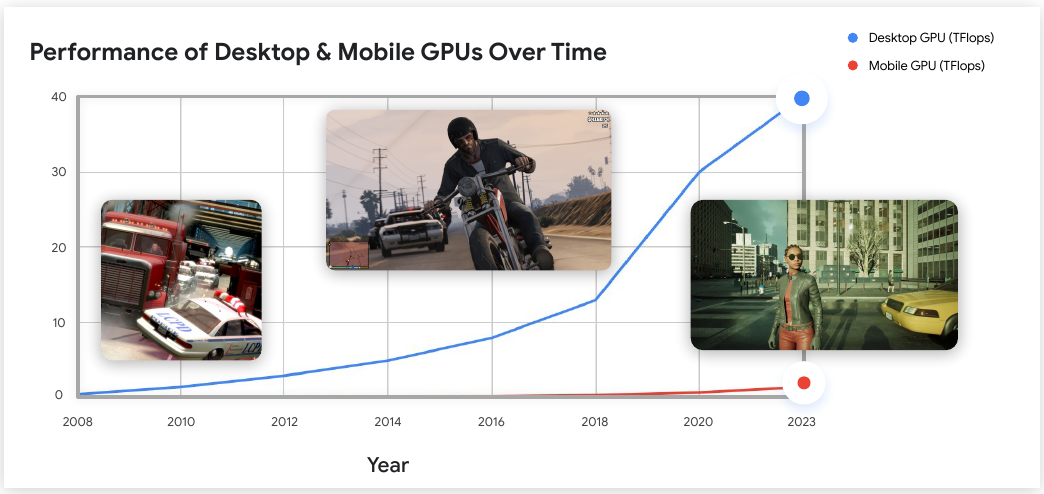
(screenshot from Developing XR Experiences for Every Device (Presented by Google Cloud) )
A potential solution arrives with XR ‘in the cloud’ – and it is evident from this year’s GTC that all the big companies are making a big play in this space and a lot of infrastructure development is going on – billions of dollars of investment. And it’s not just ‘XR’ but “XR with AI’ and high-fidelity, low-latency pixel-streaming. So, my objective is to ride on the coat-tails of this in a low-budget arty-sciencey way, and make the most of the resources that are now becoming available for free (or low-cost) as these huge industries attempt to on-board developers and explore the design-space of applications.
As you might imagine, it has been frustratingly difficult to find documentation and examples of how to go about doing this, as it is all so new. But this is what you expect with emergent and cutting-edge technologies (and almost everyone trying to make a buck off them) – but it’s thankfully something I am used to from my own practice and research: chaining together systems and workflows in the pursuit of novel outcomes.
It’s been a lot to absorb over the last few weeks, but I’m now at the stage where I can begin implementing an AI agent (using the OpenAI API) that one can query with a voice interface (and yes, it talks back), running within a cloud-hosted XR application suitable for e.g. VR HMDs, AR mobile devices, and mixed-reality devices like the Hololens 2 (I wish I had one!). It’s just a sketch at this stage, but I can see the way forward if/when I can get access to the GPT-4 API and plugin architecture, to creating a kind of Earth Observation ‘Oracle’ and a new modality for envisioning and exploring satellite data in XR.
Currently I’m using OpenAI GPT3.5-turbo and playing around with a local install of GPT4-x_Alpaca and AutoGPT, and local pixel-streaming XR. The next step is to move this over to Azure CloudXR and Azure Cognitive Services. Of course, its all much more complicated than it sounds, so I expect a lot of hiccups along the way, but nothing insurmountable.
I’ll post some technical details and (hopefully) some screencaps in a future post.
To a louse
O wad some Pow’r the giftie gie us
To see oursels as ithers see us!
It wad frae mony a blunder free us,
An’ foolish notion:
What airs in dress an’ gait wad lea’e us,
An’ ev’n devotion!
– Rabbie Burns, 1786
https://en.wikipedia.org/wiki/To_a_Louse
AR for iOS/Android in Unreal Engine 5.1
Unreal Engine is a robust platform for exploring how to develop applications in XR. So, a few weeks ago I worked through the documentation and various tutorials for developing an Augmented Reality app using Unreal Engine (UE) 5.1.
It’s confusing to say the least – as there is lots of advice available coming from different quarters, and the processes of compilation and deployment are quite complicated. Unnecessarily complicated, in my opinion – but I understand why such requirements are involved.
UE comes with an AR Template that can cross-compile for both iOS and Android. My initial thought – for ease of use – was to go and buy a cheapish Android device (tablet or phone) and deploy locally on that. But of course it isn’t that simple – there are a whole bunch of technical requirements for the platform e.g. Android OS version, CPU, GPU etc – and these must be matched with the correct Android SDK. So, a whole lot of time required to figure all that stuff out – surely there is an easier way?
There is, to a degree, on iOS, as the range of models is much more limited, and iOS seems more standardised and slightly simpler to target – despite a whole bunch of security requirements, such as developer signing certificates. Plus I already have a few iOS devices around to test on – my iPhone XR and an IPad Pro.
The next problem is that I require a recent Apple computer on which to run UE and XCode in a recent version of MacOS. These days, as I mainly develop using Windows 11 (for graphics) and Ubuntu Linux 22.04 LTS (for machine learning), this presented a problem. I have a bunch of MacPro 5,1 towers that I’ve kept as a render farm – but the most up-to-date one is a mid-2010 model, with a metal-capable Radeon RX580 GPU that was running MacOS 10.14 Mojave. This was the last OS officially supported for the ‘Classic’ Mac Pro desktop (cMP) in 2018, last updated in 2019. Lots of software was becoming ‘non-updateable’ on it, not only because it is a 13-year-old computer, but because Mojave was non-longer officially supported by Apple.
So what to do?
Fortunately there is a community of hackers who have developed work-arounds for supporting newer OS versions on unsupported machines, ranging from dosdude1’s easy-to-use MacOS patchers, to OCLP, to Martin Lo’s cMP OpenCore package. Having read around the subject and having contemplated updating my old machines for the last few years (!), I decided to take the plunge and use Martin Lo’s package, as it is specifically targeted for Mac Pro ‘cheese-graters’ like mine – with minimal patching of the underlying OS (unlike OCLP) – it is principally a modified bootloader and relatively easy to install and uninstall, without bricking your machine. There’s even a very friendly and helpful facebook group for technical discussions.
Happily it’s worked perfectly. That means I can develop as usual in Windows and use my ancient machine to deploy on iOS devices. So – I’ve got the UE 5.1 AR Template Demo compiled on MacOS Monterey 12.6.1 and XCode 14.2, running on my old cheese-grater cMP – and installed on my 2015 iPad Pro running iOS 16.3. It runs fine. Problem solved.
I have no loyalty to any particular platform - they're just systems with which to make things, and they each have their strengths and weaknesses. If possible I try and avoid vendor lock-in by exploring opensource approaches - but some degree of it seems to be unavoidable. I'm all for open standards and cross-platform compatibility. Having said this UE is my current engine of choice (though I keep abreast of Unity and Godot), and it works well enough with a broad opensource/source-available ecosystem.
Here’s a shot of it showing the default architectural model, on a placemat on a kitchen table. It works fine and has been useful for learning – but looks kind of clunky.

The following is a screenshot of the impressive AR app by Handbuilt Creative – demonstrating a photorealistic animated Psittacosaurus. There is obviously a lot of work behind this, and it indicates the level of detail that can be achieved. Of course, I would expect more recent devices would be capable of a lot more – but I don’t have the budget to just pop out and buy new tech, unfortunately, so it’s a matter of working with what I have available.

Things have progressed a great deal from here (thanks to a bunch of developments announced at GDC 2023)- I’ll cover them in a future post.
Here’s a summary of the steps to get UE 5.1 AR working, courtesy of ChatGPT:
Provisioning for iOS
If you want to distribute your iOS app made with Unreal Engine 5.1 through the Apple App Store, you will need to create a new certificate and provisioning profile for each version of your app. This is because each version of your app is treated as a separate and distinct application by Apple.
To publish your app to the App Store, you will need to create an App ID, a Distribution Certificate, and a Provisioning Profile for each version of your app. You will also need to configure your Unreal Engine 5.1 project to use these credentials for building and packaging your app.
Here are the steps you need to undertake on your Apple Developer account to create the necessary certificates and provisioning profiles for your Unreal Engine 5.1 app, as well as how to enter these details into Unreal Engine:
- Create an App ID:
- Log in to your Apple Developer account.
- Click on “Certificates, Identifiers & Profiles” in the sidebar.
- Click on “Identifiers” and then click the “+” button to create a new App ID.
- Choose “App IDs” from the “Register” dropdown menu, then select “iOS App” as the App ID type.
- Enter a name for your App ID and a unique Bundle ID (e.g. com.mycompany.myapp).
- Click “Continue” and review your App ID details, then click “Submit”.
- Create a Distribution Certificate:
- In the “Certificates, Identifiers & Profiles” section, click on “Certificates”.
- Click on the “+” button to create a new certificate.
- Select “App Store and Ad Hoc” as the certificate type and click “Continue”.
- Follow the instructions to create a certificate signing request (CSR) using Keychain Access on your Mac.
- Upload the CSR and click “Continue”.
- Download the distribution certificate and install it on your Mac by double-clicking the downloaded file.
- Create a Provisioning Profile:
- In the “Certificates, Identifiers & Profiles” section, click on “Provisioning Profiles”.
- Click on the “+” button to create a new profile.
- Select “App Store” as the provisioning profile type and click “Continue”.
- Choose the App ID you created in step 1 and click “Continue”.
- Choose the distribution certificate you created in step 2 and click “Continue”.
- Give your provisioning profile a name and click “Continue”.
- Download the provisioning profile and install it on your Mac by double-clicking the downloaded file.
- Enter the details into Unreal Engine:
- Open your Unreal Engine project and go to the “Project Settings” section.
- Under “Platforms”, select “iOS”.
- Enter your Bundle ID in the “Bundle Identifier” field.
- Click the “Import” button next to the “Certificate” field and select the distribution certificate you created in step 2.
- Click the “Import” button next to the “Provisioning Profile” field and select the provisioning profile you created in step 3.
- Save your settings and build your iOS app in Unreal Engine.
Unreal Engine 5.1 AR Documentation:
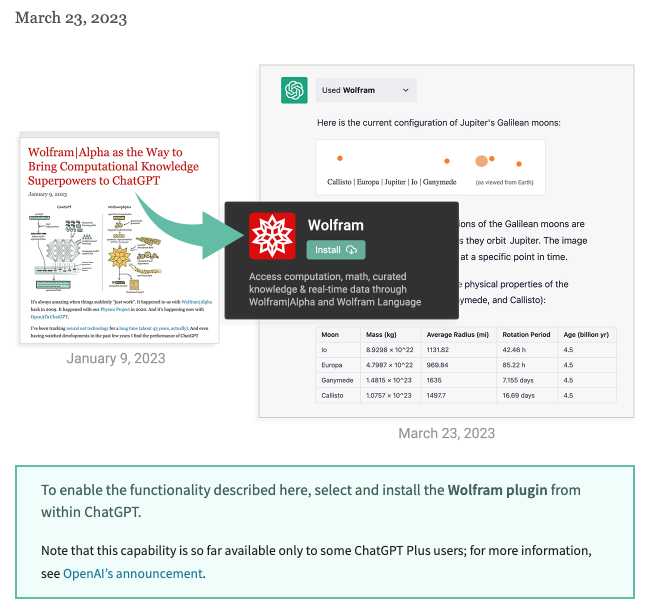
ChatGPT + Wolfram Alpha
A big moment in the history of AI, with potentially huge ramifications. As the redoubtable Jensen Huang put it – it’s AI’s ‘iPhone moment’. I’d agree with this.
ChatGPT is allowing the development of plugins:
https://openai.com/blog/chatgpt-plugins
A couple of discussions to absorb (ignore the gushy breathlessness and hype – there are some useful insights) :
I’m putting these links up as a spur to discussion, as they cover very important developments in AI and computing. Of course, the scholarly and scientific analyses of these will come later – so for now, take everything with several large grains of salt. Nevertheless, it is an instance where the rate of technological change far exceeds the rate of scientific analysis, ethical competence or legal constraint.
As these developments have only occurred within the last 24hrs or so, they have enabled me to rethink some of the approaches I’ve been taking for our residency – that I’ll detail in a future post. Exciting times!

GPT-4: a paradigm shift in the making
GPT-4: a paradigm shift in the making
Here’s the announcement video from OpenAI:
<propaganda>GPT-4 announcement video – slow panning shots of youngish people in nice rooms discussing important issues, nodding and smiling and agreeing as they type and look at screens. Apparently, these are the people working upon, deciding (ahem, asking about) your future. They’re the same as you, aren’t they? So that’s OK. But you have no real idea who they are or why they are doing this in a mix of stock imagery and apparently ‘real’ interviews. A benign info-utopia of cognitive enhancement awaits, extrapolated from everything that can be scraped from the internet (including your lifetime musings anywhere, thoughts, pictures, publications) – and that ~may~ solve your problems and ~maybe~ some other people.</propaganda>
A bit more reality:
Yep, it’s amazingly useful for programming. Really, there’s a lot to unpack in this – too much.
It’s hard to underplay the significance of this for the compute, media, cultural and economic ‘First-World’ landscape. This is the first of what will be an economic and colonial race between huge corporations and state entities for the most capable systems – it is inherently evolutionary.
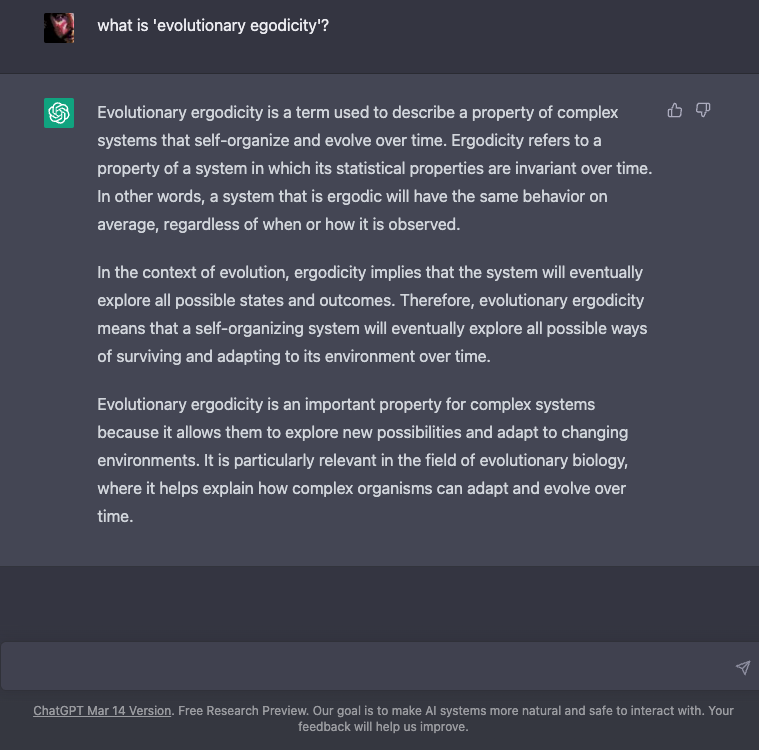
Perhaps most interesting, but unsurprising, is that the system demonstrates ’emergence’ – that there are unpredictable, non-linear capabilities that form from scale, systematic retraining and self-artifice (recursion) – as well as the evolutionary ergodicity of systems that self-organise1 – its capacity for survival (self-optimisation). It doesn’t need to be conscious or self-aware to do that – it’s an emergent property of parahuman complexity. Arguably, its creators are already its servants.
<irony>if GPT-4 aced the Bar Exam, then presumably it would objectively aid in it’s own legislation. </irony>
It’s hard to keep up with all the implications of these language models, as the rate of improvement is so astonishing – and they have such serious implications.
Below is an apparently informed but slightly breathless discussion that is interesting – now that GPT-4 has been released – with some remarkable capabilities demonstrating advanced multimodal inference and human-level common-sense.
So watch it skeptically..
For the time being, I’ll leave these here and return to programming and visualisation issues in the next few posts – assisted, of course, by my new advanced agent. And re-reading Nick Bostrom‘s book ‘Superintelligence: Paths, Dangers, Strategies, wondering what GPT-10 will be like.
It certainly won’t be an LLM. It will be a LWM.
A Large World Model – it will need to be ’embodied’ to converge to the human.
Will it have the will to will it?
Update: An interesting (and slightly alarming) addendum that is worth absorbing:
This will definitely create a lot of discussion and contention, because the ramifications are so significant.
Link to the paper:
https://arxiv.org/pdf/2303.12712.pdf
Footnotes
- ChatGPT explains: “Evolutionary ergodicity is a term used to describe a property of complex systems that self-organize and evolve over time. Ergodicity refers to a property of a system in which its statistical properties are invariant over time. In other words, a system that is ergodic will have the same behavior on average, regardless of when or how it is observed.In the context of evolution, ergodicity implies that the system will eventually explore all possible states and outcomes. Therefore, evolutionary ergodicity means that a self-organizing system will eventually explore all possible ways of surviving and adapting to its environment over time.Evolutionary ergodicity is an important property for complex systems because it allows them to explore new possibilities and adapt to changing environments. It is particularly relevant in the field of evolutionary biology, where it helps explain how complex organisms can adapt and evolve over time.”2023-03-1510.51.49pm
-
Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y.T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M.T., Zhang, Y., 2023. Sparks of Artificial General Intelligence: Early experiments with GPT-4.
Melbourne Visit


Between the 12-15 February I made my first visit to the Swinburne Centre for Astrophysics and Supercomputing – somewhat ironically housed within the old Art building on Swinburne Campus in Hawthorn. Appropriate for an Art-Science Residency I guess!
Here’s a gallery of shots to give an idea of what I saw there – it was great opportunity to meet up in person with Chris and some of the amazing team there. I’ll add more detail soon.






ChatGPT Perspectives

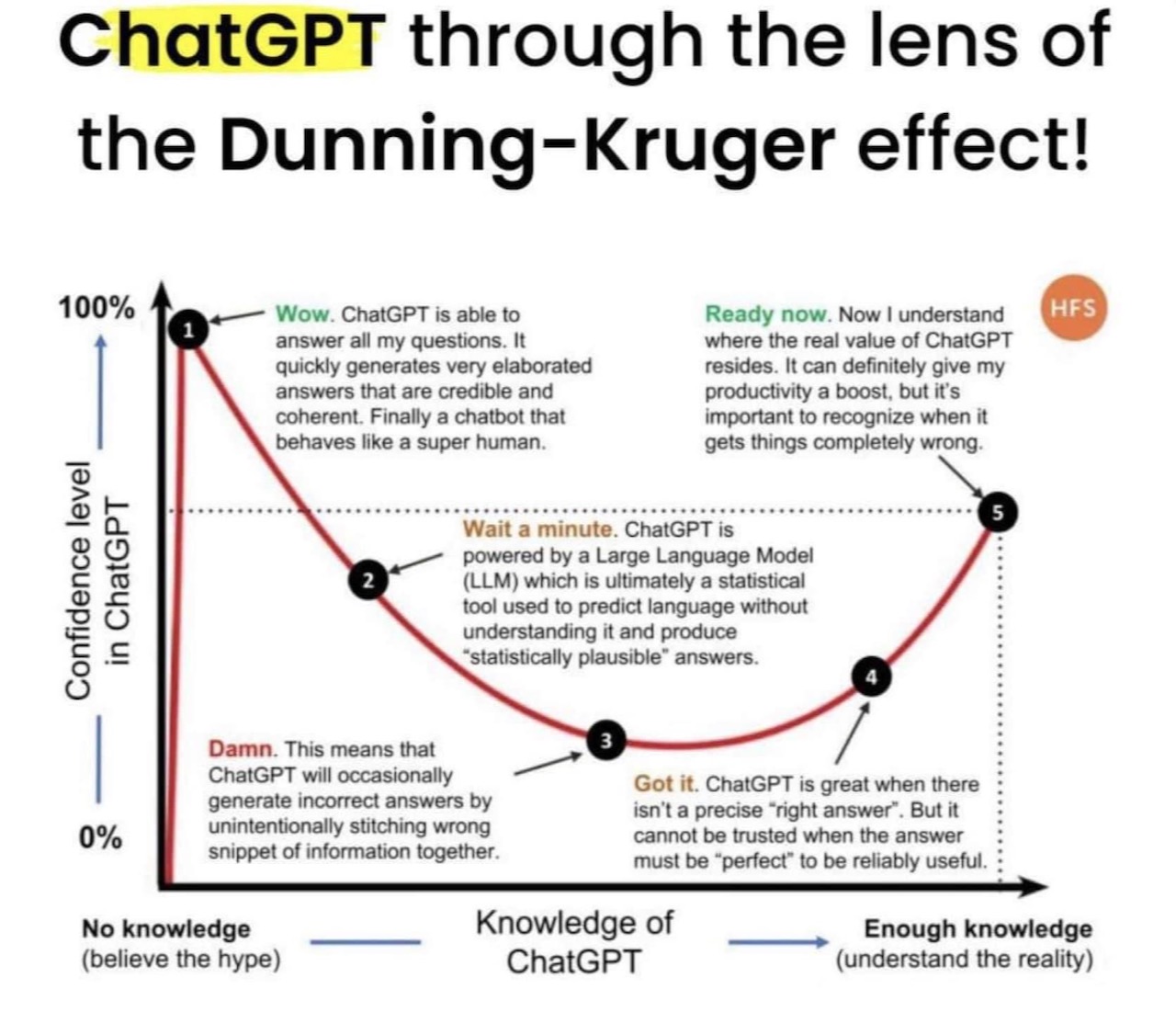
This post is a more general discussion about ChatGPT and related systems – it’s important to cut through the hype surrounding LLMs and absorb the sober scientific and cultural perspectives and questions around these systems and their capabilities. The impacts of these systems for knowledge work and creative work is going to be huge in the near future – so time to start understanding their context and implications.
S. Wolfram : What Is ChatGPT Doing … and Why Does It Work?
This is an excellent technical discussion about how Neural Nets (NNs) work, with interesting questions about the internal ‘black box’ goings-on – that are in general quite inscrutable. Wolfram is arguing for a rigorous scientific understanding of NNs, as they seem principally to have arisen as engineering exercises – things that work, but no-one really understands exactly why (‘lore’ in Wolfram’s estimation). This is a sharp counterpoint to the feuilleton hype about AI (which is, really, ‘Machine Learning’, or ‘Machine Representation’, as it is not ‘truly’ intelligent or aware). He makes interesting points about interfacing something like ChatGPT with Wolfram Alpha, which is a kind of computational knowledge engine, and argues convincingly that an interface between the two systems could solve many of the factual errors confabulated by the LLM, and provide something much more powerful in combination: a system that is ‘factually’ connected to the ‘world’ – and perhaps even capable of causal inference as a result.
The discussion touches upon several interesting philosophical/theoretical areas concerning the construction and emergence of language and discourse.
Human language—and the processes of thinking involved in generating it—have always seemed to represent a kind of pinnacle of complexity. And indeed it’s seemed somewhat remarkable that human brains—with their network of a “mere” 100 billion or so neurons (and maybe 100 trillion connections) could be responsible for it. Perhaps, one might have imagined, there’s something more to brains than their networks of neurons—like some new layer of undiscovered physics. But now with ChatGPT we’ve got an important new piece of information: we know that a pure, artificial neural network with about as many connections as brains have neurons is capable of doing a surprisingly good job of generating human language. (Wolfram, 2023)
Of great interest to me is the possibility of what one might call ’empirical semiotics’ or ‘computational semiotics’ – where semiotic generation and analysis (semiosis) could be underpinned by computational forms of emergence, categorisation and logic.
The success of ChatGPT is, I think, giving us evidence of a fundamental and important piece of science: it’s suggesting that we can expect there to be major new “laws of language”—and effectively “laws of thought”—out there to discover. In ChatGPT—built as it is as a neural net—those laws are at best implicit. But if we could somehow make the laws explicit, there’s the potential to do the kinds of things ChatGPT does in vastly more direct, efficient—and transparent—ways. (Wolfram, 2023)
Presumably many of these ‘laws’ are already uncovered or at least hinted-at by research in NLP and computational language models – but it appears very much a contentious field – especially with regard to what any formulation of what ‘intelligence’ is.
If there is one constant in the field of artificial intelligence it is exaggeration: There is always breathless hype and scornful naysaying. It is helpful to occasionally take stock of where we stand. (Browning & LeCun, 2022b)
To me it seems important to understand LLM cognates and extensions in multimodal systems – that intelligent systems can draw inferences across visual, audial, somatic and other sensory modalities beyond the textual and linguistic (Browning & LeCun, 2022a).
The underlying problem isn’t the AI. The problem is the limited nature of language. Once we abandon old assumptions about the connection between thought and language, it is clear that these systems are doomed to a shallow understanding that will never approximate the full-bodied thinking we see in humans. In short, despite being among the most impressive AI systems on the planet, these AI systems will never be much like us.(Browning & LeCun, 2022a).
The field of semiotics has a significant body of work covering these differing/interdependent signifying regimes – but not a great deal that is computationally reducible, as it has been more in the form of ‘literary criticism’ or humanities ‘theory’ (including in my own research background). This is clearly inadequate for a scientific approach as it is far too qualitative – more ‘top down’ than ‘bottom up’ – reminiscent of debates concerning symbolic reasoning vs (what might be termed) ’emergent’ reasoning. However, there are examples in the work of C.S. Peirce, M.A.K. Halliday and others that may be useful for thinking about this domain. In the area of cognitive neuroscience/neuroanthropology I immediately think of the work of T. Deacon, A. Damasio, D. Deutsch, J. Hawkins and others that synthesise this inter-disciplinary domain of knowledge into useful ways of thinking about what might constitute an intelligent system and how it might emerge.
For non-specialists like me there is much to absorb – that can inform ways of critically engaging with this novel technology.
It is terribly important to not be naive about this stuff (AI), as it will (and has already) have transformational impacts upon personhood, economic, political and natural systems, for good and for bad. It is hard to imagine a future when a self-aware, agentive machine intelligence is more than a science ‘fiction.’ It sounds absurd, but perhaps it isn’t.
Imagine a world where people’s online images, text, music, voice recordings, videos, and code get gathered largely without consent to train AI models, and sold back to them for $10 a month. We’re already there but imagine something beyond that – and assume it’s incredible…
…Here’s a thought experiment: imagine an AGI system that advises taxing billionaires at a rate of 95 percent and redistributing their wealth for the benefit of humanity. Will it ever be hooked into the banking system to effect its recommended changes? No, it will not. Will those minding the AGI actually carry out those orders? Again, no.
No one with wealth and power is going to cede authority to software, or allow it to take away even some of their wealth and power, no matter how “smart” it is. No VIP wants AGI dictating their diminishment. And any AGI that gives primarily the powerful and wealthy more power and wealth, or maintains the status quo, is not quite what we’d describe as a technology that, as OpenAI puts it, benefits all of humanity. (Claburn, T. , The Inquirer, 2023)
We don’t have a good definition of intelligence – so it seems best to define it operationally (as Friston et. al. 2022 does). At this stage the take-away is that LLM’s are clearly what the label says: they are language models, not artificial intelligences – they are, literally, Rhetorical Devices.
LLMs statistically parameterise a huge amount of ‘knowledge’ about linguistic representations of the world – based upon their massive set of ‘training’ data. These terms are information, signs, similes, metaphors, metonyms, synedoches – abstractions that can exhibit indefiniteness: degrees of epistemic and ontic undecidability or infinite regression. Uncertainty.
LLMs seem to respond dialogically, perhaps following chains of reasoning akin to the vectors in ‘meaning space’ that Wolfram discusses (’embeddings’ – examples of t-SNE or word2vec dimensional reduction plots). These dialogues can also be guided by user interaction via the Chatbot query interface through ‘chain-of-thought’ reasoning – which demonstrably improves the model performance (even, it seems, when the model performs what might be the equivalent of ‘self-talk’).
Larger models seem to improve inferential reasoning – yet presumably there will be drawbacks or limits in a scale-only approach. Not least amongst these being the prodigious amounts of compute required, and their concomitant use of electricity and consequent carbon-impacts.
Are they ’emulations’ or ‘simulations’? What would this distinction imply?*** To me, it indicates that it (an LLM) is a map, not an actor; a palimpsest, not an agent.
A counterpoint.
At no point with chatGPT is there any self-initiation. Purpose and curiosity, at this juncture, seem very much a human property. Whether this will continue to be the case, time will tell.
For our current purposes we can be reasonably confident about the ongoing necessity of the ‘human-in-the-loop’ approach we’re pursuing. For the time being. And with which humans?
*ChatGPT apparently implements this type of response training interface – thumbs-up/thumbs-down.
***Thanks to my colleague P. Bourke for drawing this distinction to my attention.
References
Altman, S., n.d. Planning for AGI and beyond [WWW Document]. OpenAI. URL https://openai.com/blog/planning-for-agi-and-beyond#SamAltman (accessed 3.10.23).
Ananthaswamy, A., 2023. In AI, is bigger always better? Nature 615, 202–205. https://doi.org/10.1038/d41586-023-00641-w
Browning, Jacob, and Yann LeCun. “What AI Can Tell Us About Intelligence,” June 16, 2022. https://www.noemamag.com/what-ai-can-tell-us-about-intelligence.
Browning, Jacob. “AI And The Limits Of Language,” August 23, 2022. https://www.noemamag.com/ai-and-the-limits-of-language.
Claburn, T., n.d. OpenAI CEO heralds AGI no one in their right mind would want [WWW Document]. URL https://www.theregister.com/2023/02/27/openai_ceo_agi/ (accessed 3.10.23).
Daull, Xavier, Patrice Bellot, Emmanuel Bruno, Vincent Martin, and Elisabeth Murisasco. “Complex QA and Language Models Hybrid Architectures, Survey.” arXiv, February 17, 2023. http://arxiv.org/abs/2302.09051.
Deacon, Terrence W. Incomplete Nature: How Mind Emerged from Matter. WW Norton & Company, 2011.Deacon, Terrence W. The Symbolic Species: The Co-Evolution of Language and the Brain. WW Norton & Company, 1998. ISBN:9780393049916
Dennett, D.C. Consciousness Explained. Little, Brown, 2017. ISBN: 0-316-18065-3
Deutsch, David. The Beginning of Infinity: Explanations That Transform The World. Penguin UK, 2011. ISBN: 9780140278163
Friston, Karl J, Maxwell J D Ramstead, Alex B Kiefer, Alexander Tschantz, Christopher L Buckley, Mahault Albarracin, Riddhi J Pitliya, et al. “Designing Ecosystems of Intelligence from First Principles,” December 2022. https://doi.org/10.48550/arXiv.2212.01354.
Halliday, Michael Alexander Kirkwood. Language as Social Semiotic. London Arnold, 1978. ISBN:9780713159677
Hawkins, Jeff. A Thousand Brains: A New Theory of Intelligence. Hachette UK, 2021. https://doi.org/10.26613/esic.6.1.282
Huang, Jiaxin, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. “Large Language Models Can Self-Improve.” arXiv, October 25, 2022. http://arxiv.org/abs/2210.11610.
Ouyang, Long, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, et al. “Training Language Models to Follow Instructions with Human Feedback.” arXiv, March 4, 2022. http://arxiv.org/abs/2203.02155.
Pearl, J., Mackenzie, D., 2018. The Book of Why: The New Science of Cause and Effect. Penguin UK. ISBN: 9780141982410
Savage, N., 2023. Why artificial intelligence needs to understand consequences. Nature. https://doi.org/10.1038/d41586-023-00577-1
Tanaka-Ishii, K., 2010. Semiotics of Programming. Cambridge University Press. ISBN:9780521516556
Tenachi, W., Ibata, R., Diakogiannis, F.I., 2023. Deep symbolic regression for physics guided by units constraints: toward the automated discovery of physical laws. https://doi.org/10.48550/arXiv.2303.03192
Massimini, M., Tononi, G., 2018. Sizing Up Consciousness: Towards an Objective Measure of the Capacity for Experience. Oxford University Press. ISBN:9780198728443
Wolfram, Stephen. “What Is ChatGPT Doing … and Why Does It Work?,” February 14, 2023. https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/.